
Introduction 🔗
Continuous Integration / Deployment and Delivery (CI/CD) pipelines are at the heart of any modern software development process. Testing and deploying code upon a commit to the version control system (VCS) are the cornerstone of being able to react quickly to changes. I was itching to build such a system on my own for some time now. And on top of that, I wondered if it was possible to make it serverless, so that there were no costs if nothing is committed or deployed. The result is “drizzle”. An experimental CI/CD pipeline based on AWS Lambda.
Prerequisites 🔗
This post assumes that you have basic AWS knowledge and that you are familiar with AWS tooling such as AWS CDK and AWS CLI. Basic Golang knowledge is also beneficial.
Overview - How does it work? 🔗
The following picture is an architectural overview of the AWS components used in drizzle:
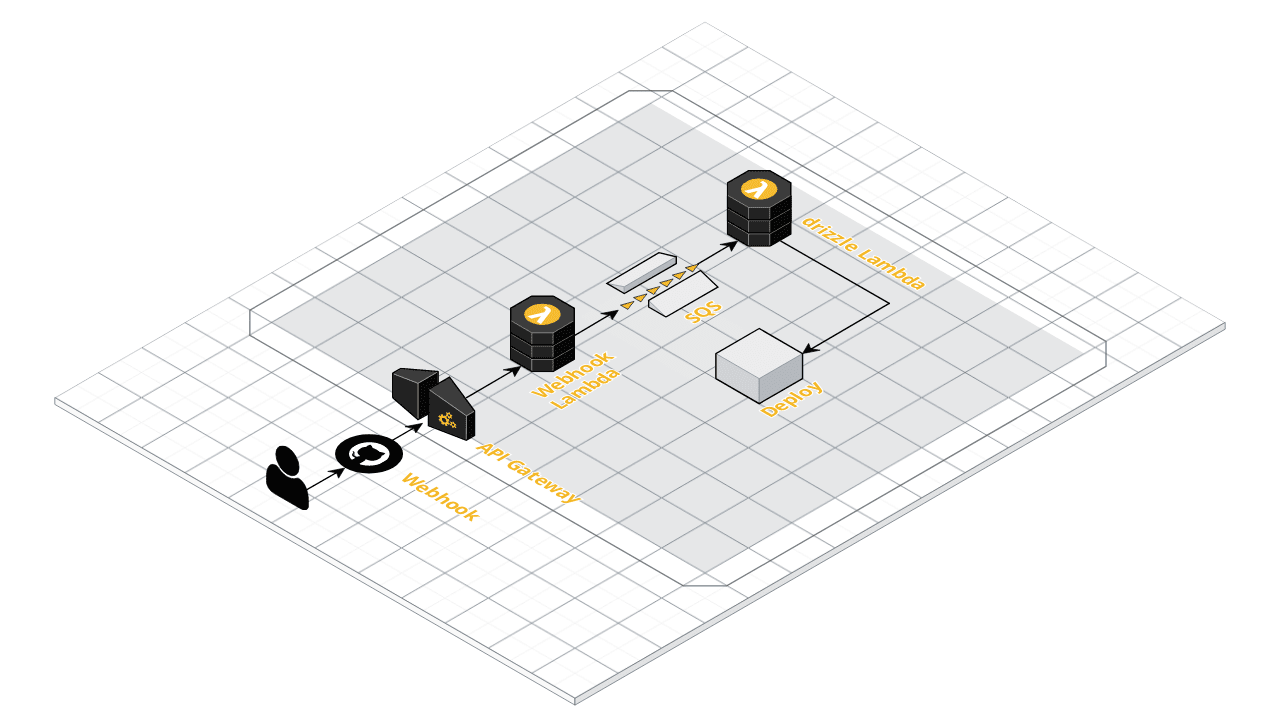
If validation is successful, we send a message to a SQS queue and return HTTP status 200 to GitHub. If not, we return with a respective HTTP error code. The SQS queue then triggers the drizzle Lambda function, which does the actual work. It clones the repository contained in the Webhook request and executes a build script, which is located in the root folder of the repository.
Configuration 🔗
Permissions of the AWS components and all configuration happen in a CDK script. The drizzle Lambda function is able to retrieve variables from the Lambda environment as well as secrets from the AWS Secrets Manager. Hence, there is no need to store sensitive information in the build configuration yaml file. If you need a new secret, you simply add it to the Secrets Manager and make it available in the CDK script. In case you want to enable a new environment variable, you also add it to the CDK script. On the same note, if the Lambda needs permissions to, say, copy files to S3, you just add the permission to the CDK script.
Building with Go in a Lambda environment 🔗
Note the environment variables of the drizzle Lambda:
const pipelineLambda = new lambda.DockerImageFunction(this, 'drizzle-pipeline', {
...
environment: {
GOCACHE: '/tmp/gocache',
GOMODCACHE: '/tmp/gomodcache',
WORK_DIR: '/tmp',
...
}
})
AWS only permits write access to the file system in the /tmp folder. Hence, we have to configure our execution
environment to adhere to this constraint. Luckily, you can tell Go exactly where to find the desired files.
Private repositories 🔗
You can also use private repositories. The drizzle Lambda function follows the convention that if the repository is
marked as private in the webhook request, it tries to access a secret from the Secret Manager with the repository ID.
Hence, if you want to use a private repository, you have to create a new secret which contains your GitHub access token.
Keep in mind though that each secret will cost a fixed amount of money each month (at the point of writing ~0,40 € in
the EU Central Frankfurt region).
To add a private repository GitHub token to AWS, you have to add it to the Secrets Manager as a pre-existing secret.
The recommended way is to manually provision the secret in the SecretsManager and use the Secret.fromSecretArn
or Secret.fromSecretAttributes method to make it available in your CDK application.
In the CDK script, it looks like this:
const repositorySecret = secretsManager.Secret.fromSecretAttributes(this, "repository-secret", {
secretArn: "arn:aws:secretsmanager:<REGION>:<ACCOUNT_ID>:secret:GITHUB_REPOSITORY_<ID>-dn5TAx"
});
repositorySecret.grantRead(pipelineLambda)
Script execution 🔗
To configure the build pipeline we will use a yaml file, where we can configure variables, stages and execution steps.
To be able to run a pipeline on a repository we add .drizzle.yml at the root folder of our repository.
An example file looks like this:
variables:
PATH: '/test/kk'
stages:
- name: build
execute:
- go build
- name: test
execute:
- go test ./...
- golint ./...
Each stage and each command is processed from top to bottom.
If we only want the command to be executed on a specific branch (e.g. “main”) we can add the branches section to a stage.
For example, if we want to execute the deploy stage only on main we add the following:
stages:
- name: deploy
branches:
- main
execute:
- aws s3 sync public s3://$S3_BUCKET --delete
Our build environment (in the example code it is Go) can be adapted in the drizzle Dockerfile. For example, if you wanted to build a Node.js deployment package, you would have to add Node together with npm to the Dockerfile.
Here is an actual .drizzle.yml, which is used to deploy this website:
variables:
S3_BUCKET: '$UPHILL_WEB_S3_BUCKET'
CF_DISTRIBUTION_ID: '$UPHILL_CF_DIST_ID'
stages:
- name: build
execute:
- HUGO_ENV=production hugo
- name: deploy
execute:
- aws s3 sync public s3://$S3_BUCKET --delete
- name: invalidate_cache
branches:
- main
execute:
- aws cloudfront create-invalidation --distribution-id $CF_DISTRIBUTION_ID --paths '/*'
- name: commit
execute:
- git add . && git add -u && git commit -m "drizzle-pipeline Update hugo public folder" && git push
To see any command output or error, you can mark a stage with debug: true. Every console out (without resolved secrets)
will then appear in the AWS CloudWatch log of the drizzle Lambda for you to review:
stages:
- name: build
debug: true
execute:
- HUGO_ENV=production hugo
How to run 🔗
We clone the following repositories into the same folder:
Afterwards, we execute the CDK project (drizzle-infrastructure). It will build and deploy the Lambda functions as well as create the infrastructure in your AWS account. Details on how to execute the CDK project can be found in the readme file of the project and in my previous post.
In the next step we need to configure our repository to send webhook requests to the API Gateway endpoint. See also my
previous post for detailed instructions.
Then, we add a .drizzle.yml file to our repository and the pipeline should be running, assuming it is a public repository.
Why two Lambdas? 🔗
This could also be done with just one Lambda function. However, the build itself takes significantly longer than request timeout of GitHub (which I guess is just about 10 seconds), after which the request is marked as failed. So we would not be able to distinguish a failed request from a successful one.
Why the SQS queue? 🔗
We could certainly also trigger the drizzle Lambda function from within the webhook Lambda. However, I think it is neat to have potential builds actually line up in a queue.
Outlook 🔗
Although this is purely experimental code, it would be interesting to add the following features:
- Store the result of each build and the console output in case of an error.
- Add notification mechanism. For example via Slack, email etc.
- Add rudimentary UI for reviewing console out, retry failed builds or trigger new builds.
Conclusion 🔗
Secrets stay within your AWS infrastructure and can be managed via the AWS Secrets Manager in conjunction with CDK. It is also a cost-sensitive setup, since you just pay for the execution of your Lambda functions, a bit for the SQS queue and the secrets. The biggest cost factor certainly are the secrets, as they will cost you regardless of execution. You can enable the Lambda function to deploy all sorts of things in your AWS infrastructure, or anywhere else if you like. However, please note that this is purely experimental code and should probably not be used in production.
Moreover, this setup makes no sense for big projects. You are limited by all Lambda restrictions, especially temporary folder size, execution time and memory. If you have hundreds or even thousands of commits and deployments a day, a dedicated CI/CD system is the better choice.
Also, it is quite easy to get all your secrets from Secret Manager and print them out. Keep in mind that this is supposed to run within your own infrastructure, where you could do anything you like anyway.
Nevertheless, this was a fun experiment, and I actually use the setup to deploy this website. Feel free to have a look at the code and shoot me an email with your thoughts and comments.